20行代码轻松爬取bilibili任意关键词搜索结果
需要准备的库
- BeautifulSoup
- requests
- re
打开哔哩哔哩主页:
在搜索框中随意输入内容
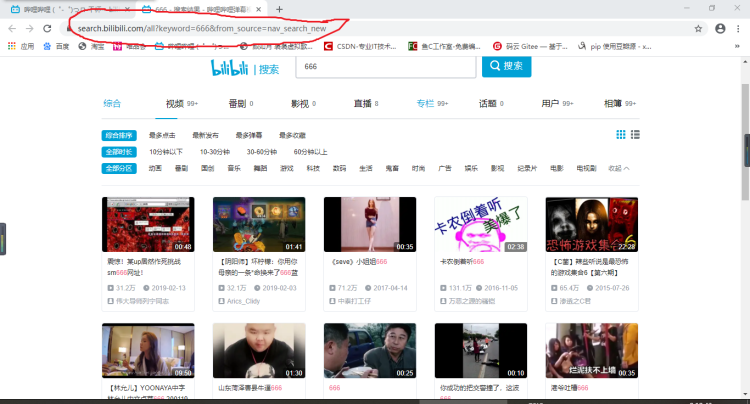
点击开发者工具左上角的按钮,将鼠标移动到第一个视频位置
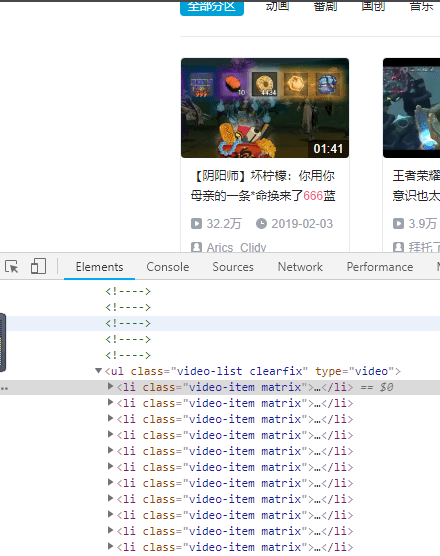
打开标签,找到li标签下a标签的一条href信息,href指向的链接就正是我们搜索结果的视频地址
接着用同样的方法打开其他搜索结果的href链接,可以看到规律如下
http://www.bilibili.com/video/av 接视频id
我们的爬虫要做的就是模仿我们搜索的过程以及爬取每一个li表情下的href链接,也就是爬取视频链接
接着我们可以在此基础上让程序变得更灵活:
- 自动存入文件
- 自动保存视频
放代码…
from bs4 import BeautifulSoup
import requests
import re
kewword=input('输入关键词:')
html_doc = "https://search.bilibili.com/all?keyword="+kewword+"&from_source=nav_search_new"
mode=int(input('是否存入文件'))
req = requests.get(html_doc)
req.encoding='utf-8'
html=req.text
soup = BeautifulSoup(html,'html.parser')
list_=[]
for k in soup.find_all('a'):
list_.append(k.get('href'))
for i in list_:
if i and i.find('www.bilibili.com/video/av')!=-1:
if not mode:
print(i)
else:
with open('bilibili website.txt','a') as f:
f.write(i+'\n')程序完成
